


Jupyter Notebooks have three particularly strong benefits:
- They’re great for showcasing your work. You can see both the code and the results. The notebooks at Kaggle are particularly great examples of this.
- It’s easy to use other people’s work as a starting point. You can run cell by cell to better get an understanding of what the code does.
- It's very simple to host server side, which is useful for security purposes. A lot of data is sensitive and should be protected, and one of the steps toward that is that no data is stored on local machines. A server-side Jupyter Notebooks setup gives you that for free.
When prototyping, the cell-based approach of Jupyter Notebooks is great. But you quickly end up programming several steps — instead of looking at object-oriented programming.
Downsides of Jupyter Notebooks
When you’re writing code in cells instead of functions/classes/objects, you quickly end up with duplicate code that does the same thing, which is very hard to maintain.
Don’t get the support from a powerful IDE.
Consequences of duplicate code:
- It’s hard to actually collaborate on code with Jupyter — as we’re copying snippets from each other it’s very easy to get out of sync
- Hard to maintain one version of the truth. Which one of these notebooks has the one true solution to the number of xyz?
There’s also a tricky problem related to plotting. How are you sharing plots outside of the data science team? At first, Jupyter Notebooks is a great way of sharing plots — just share the notebook! But how do you ensure the data there is fresh? Easy, just have them run the notebook.
But in large organizations, you might run into a lot of issues as you don’t want too many users having direct access to the underlying data (for GDPR issues or otherwise). In practice, in a workplace, we’ve noticed plots from Jupyter typically get shared by copy/pasting into PowerPoint. It’s highly ineffective to have your data scientists do copy/paste cycles whenever the data changes.
An example
Let’s look at an example notebook from Kaggle.
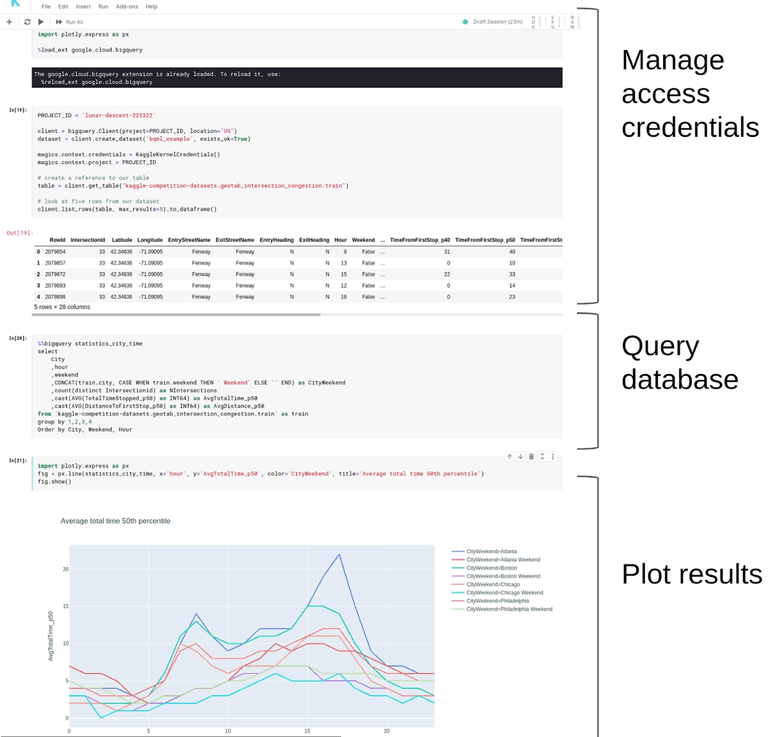
This was very easy to get started on. I just copied some cells from the introductory examples and then explored on my own. But here we also see the downside — access-credentials management is now duplicated across all of the notebooks. What if they change? Then, every notebook needs to be changed as well.
The dataset is interesting. But there’s no canonical one — so if you want to reuse it, you’re copying the SQL statement.
With poor discipline, you can also move into weird versioning issues where you start accumulating multiple Jupyter Notebooks that no one remembers.
Benefits from an IDE
As alternatives to Jupyter Notebooks, you could check out Spyder and PyCharm.
Spyder has an interesting feature where it’s very good at reloading code while keeping the state of your current session. Thus, Spyder is great if you’re trying to do most of your transformations in pandas or some other tool on your local machine. It also comes with Anaconda, if that’s your Python distribution of choice.
PyCharm is really good at building proper Python code and getting replicable results. There’s a lot of functionality for greater productivity. Both Spyder and PyCharm enable cell-based processing with #%% comments in your code, so we can still prototype code in the same way as in Jupyter Notebooks.
For one of our previous clients, we wanted to improve code quality, but we were not allowed to access data on any local machines. So we spent the effort to spin up VMs with PyCharm to get access to data in a secure manner. It paid off quickly — development speed and code quality increased by a factor of a lot. And code made it into production a lot faster as well.
Getting machine learning into production
Something to think about is where computations run. For code that’s easy to put into Docker, deploying that to any cloud solution is easy. For Notebooks, there are also good options, though you’re more locked into specific solutions.
If you do want to look into Jupyter Notebooks, it’s definitely worth looking into Amazon SageMaker and/or Kubeflow. These solutions enable easier deployment to production for code in Notebooks.
We’ve had a lot of success with the following approach:
- Use PyCharm (which has improved code quality by a fair bit).
- Every transformation of data needs to exist in exactly one place in our repository. (So any issue with that transformation needs to be fixed in that one place.).
- Every transformation needs to be in production (so available as a table/file/output), so other data scientists can reuse it in their models. And if that transformation improves, all subsequent pipelines are automatically improved as well.
Conclusion
Should you remove Notebooks completely? Notebooks have a lot of pros. It depends on where you are and what your main concerns are:
- If all of the machine learning is already on the cloud and only needs some light scripting — Notebooks are probably the easiest way there.
- Be careful with a heavy reliance on Notebooks when the data engineering team is short staffed or when the data scientist team is immature — as this is when you can build up an unmanageable amount of bad habits and technical debt in a short amount of time.
- If your problems are fairly unique and require a lot of self-developed code, Jupyter Notebooks will grow in size and complexity in ways that will be hard to maintain.
- The larger the team, the more concerns we have about collaborative coding and the reuse of results between team members, and we should be moving away from Jupyter.
- If you have cross-functional teams, with both software engineers and data scientists, getting the most out of version control and object-oriented programming is easier. If you have a cross-functional team, you’ll probably get more benefits by moving away from Jupyter.
By Steffen Sjursen